苏州盘首数据恢复
苏州盘首数据恢复 数据恢复问题可微信咨询
数据恢复问题可微信咨询 你好朋友,
有时我们必须使用格式化的驱动器。 大多数文件系统都有从格式化驱动器恢复数据的特殊规则。 有时,我们使用格式化的RAID阵列。 对于RAID情况,有不同的数据恢复规则,但是主要原理仍然相同。
在今天的情况下,我们在6个驱动器上有一个RAID阵列。 根据主要分析,对每个磁盘的前125,000,000个扇区进行了格式化:将它们填充为零,并为整个RAID阵列创建了新的MBR + GPT。
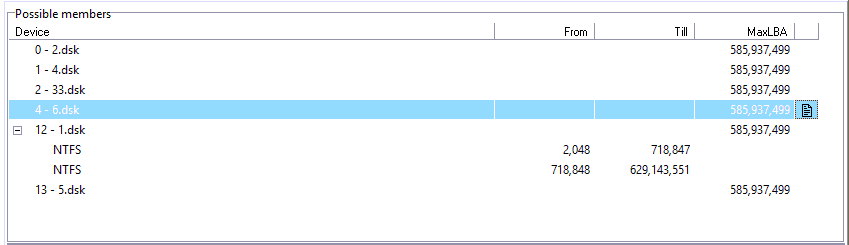
我们的策略是寻找位于格式化区域之后的数据。 为了实现这一目标,我们专注于预先格式化的文件系统结构,而不是新的结构。 在RAID Edition工作区中添加所有成员

从RAID阵列恢复数据的RAW恢复和统计数据。 我们对125,000,000个扇区之后的所有成员启动RAW恢复,并检查结果。
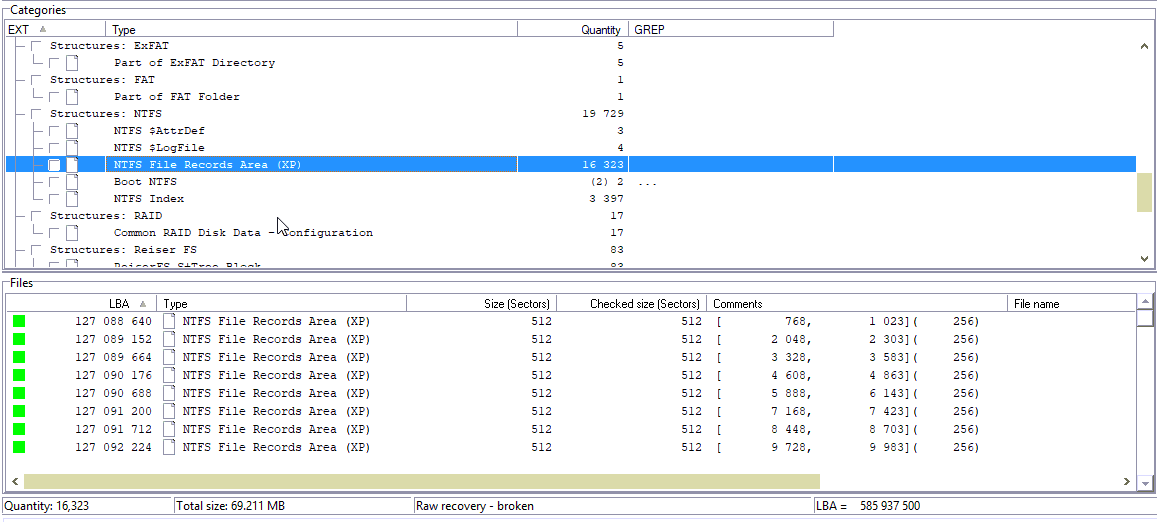
关键是要获得有关块大小的信息。 在这里,是512个扇区。
下一步是进入统计并选择块大小512。
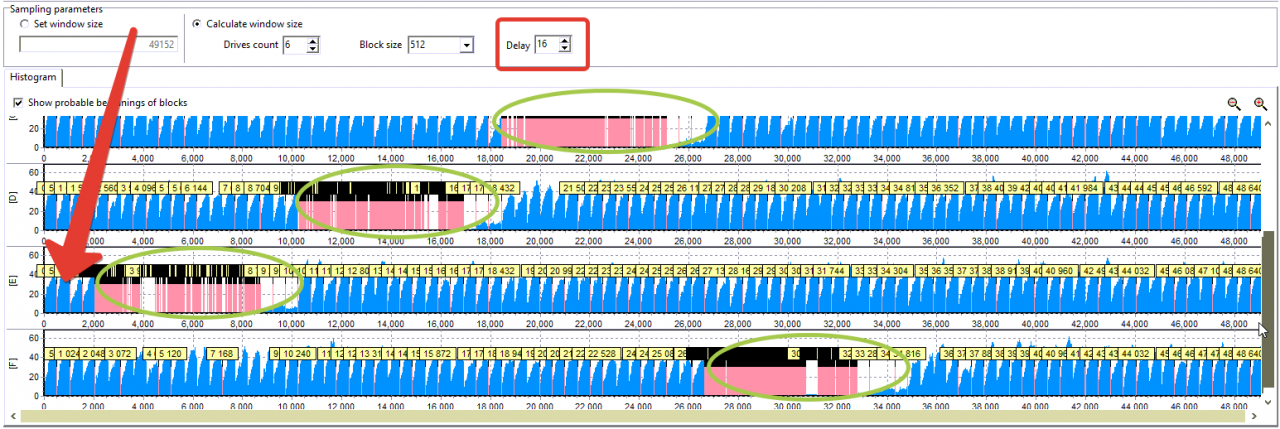
将驱动器计数设为6,并将启动延迟设置为1。
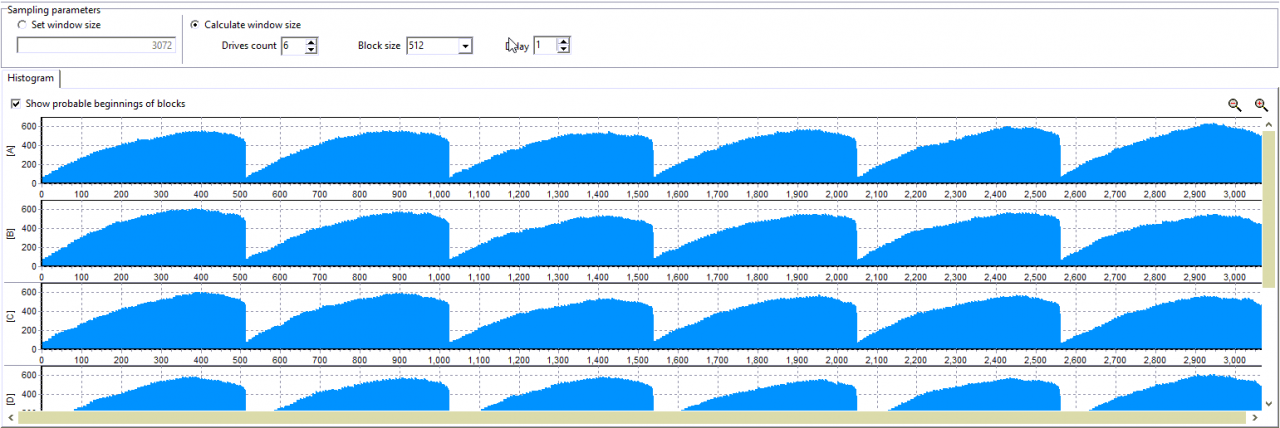
在此图表上看不到周期结构。 让我们尝试将延迟值设置为16。
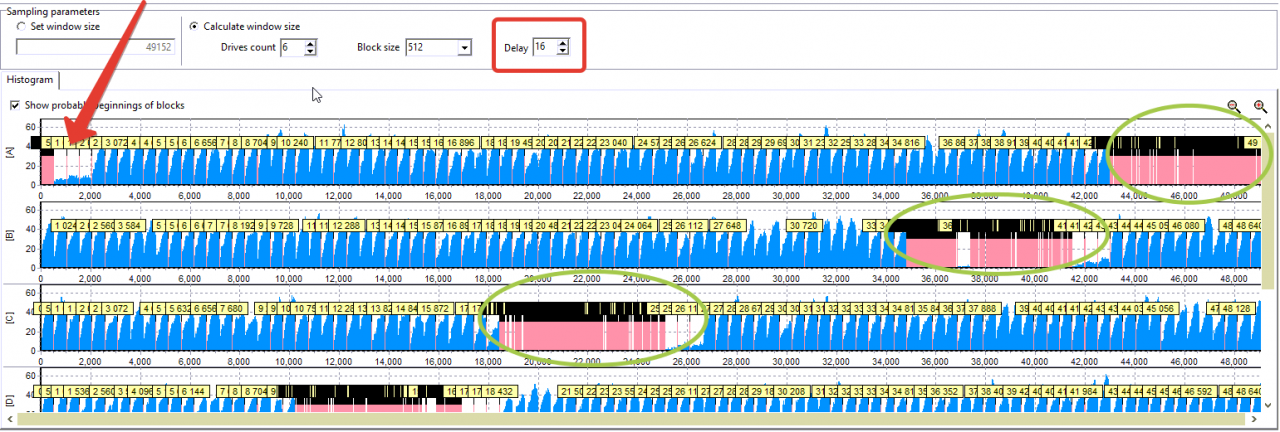
该图表说明了前4个磁盘的XOR区域。 此外,它表明,从〜2000个扇区开始,会有一些变化。
其他磁盘的图片相同。
开始时的转移建议我们定义分区的开始(可能是用于软件RAID的RAID阵列)。 那我们在哪里呢? 是的,在RAW恢复中。
它在这里:
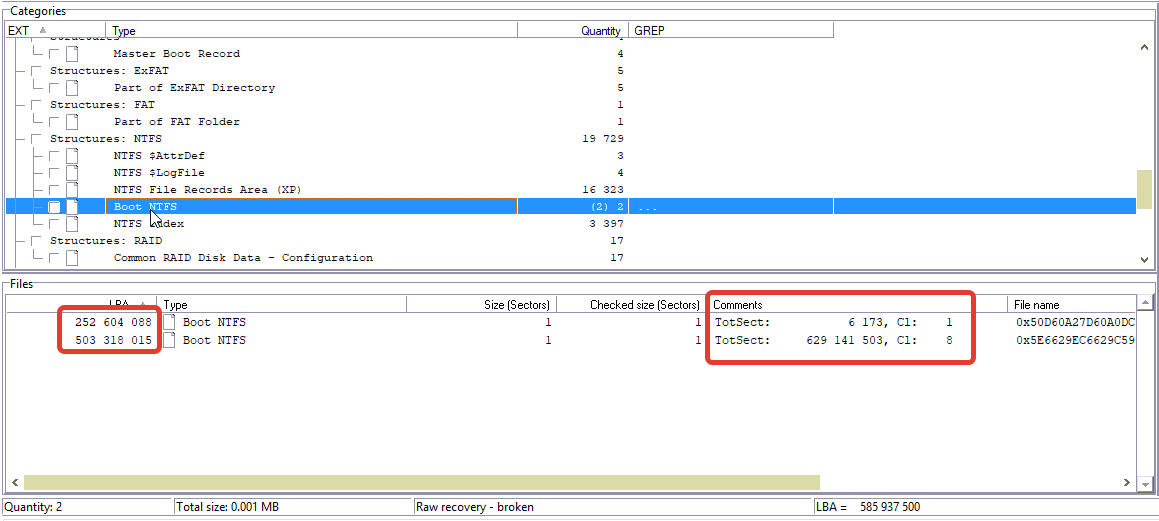
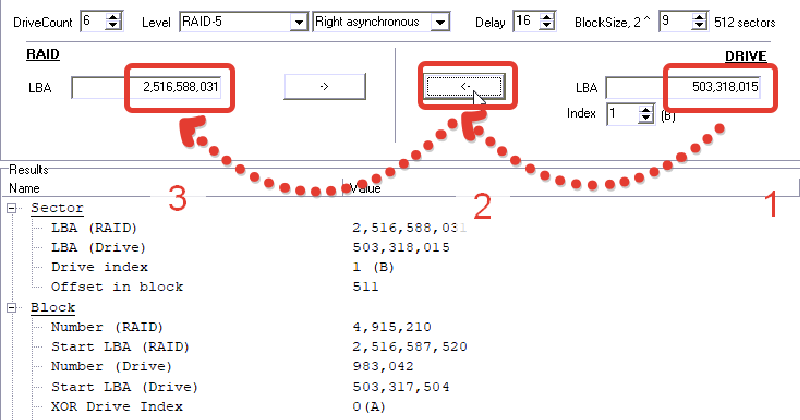
我们对503,318,015(LBA)的更大分区感兴趣。 复制此LBA。
下一个有用的工具是计算器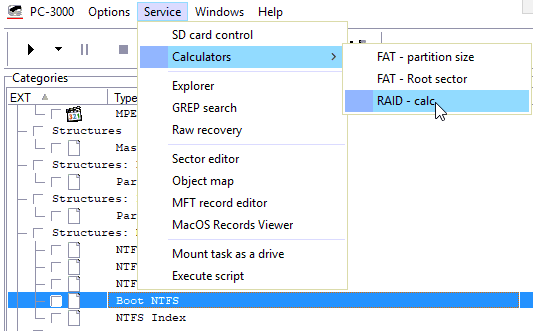
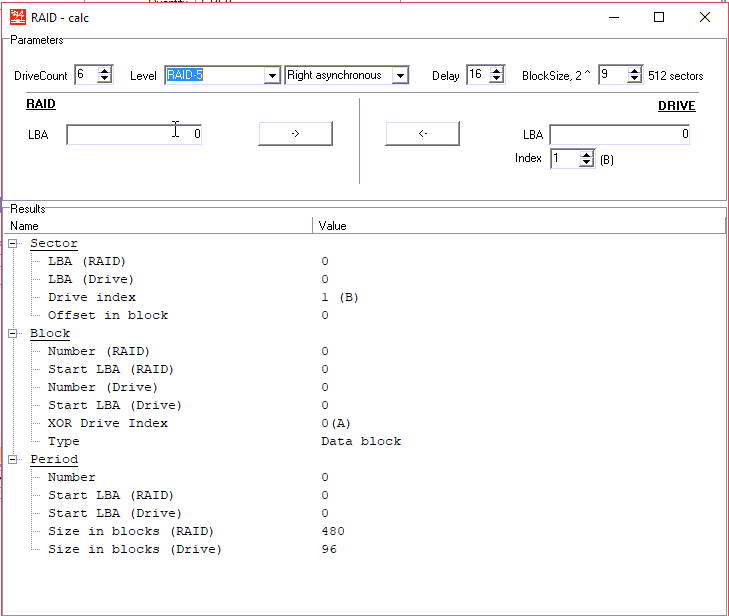
在右侧,我们粘贴了NTFS引导的LBA。
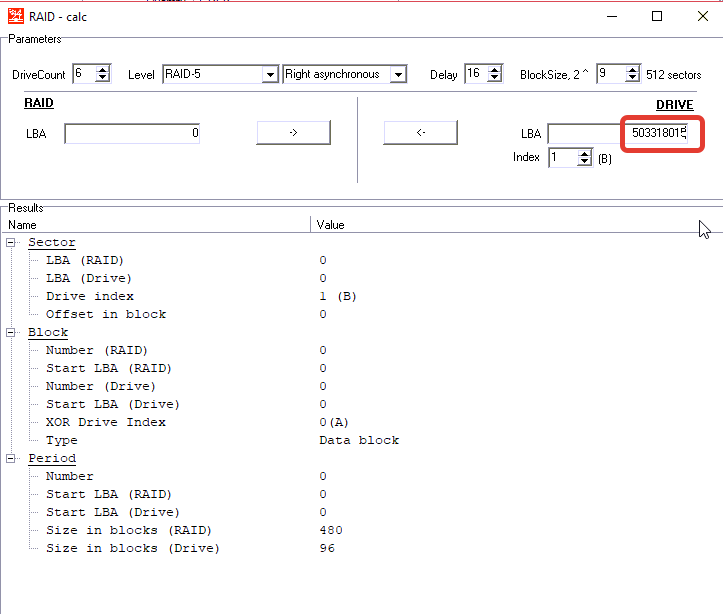
在左侧,我们在RAID阵列上获得此启动的近似LBA

复制此值
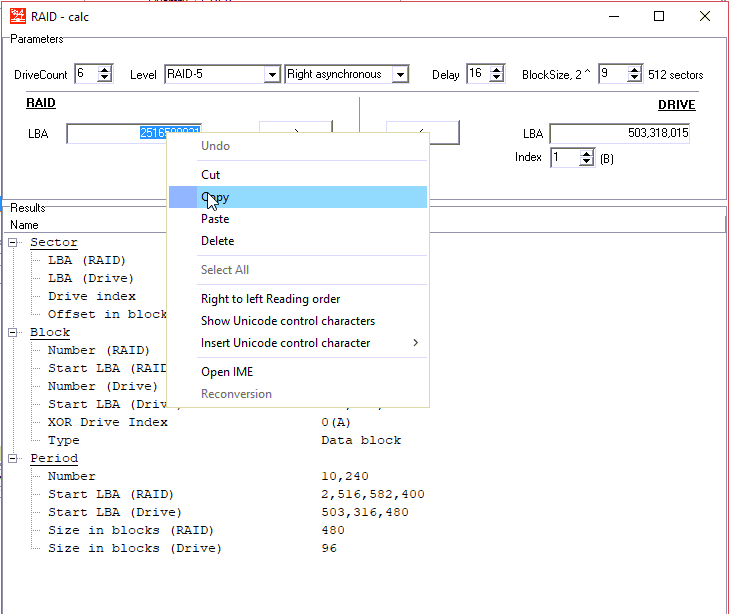
并在RAID配置上寻找
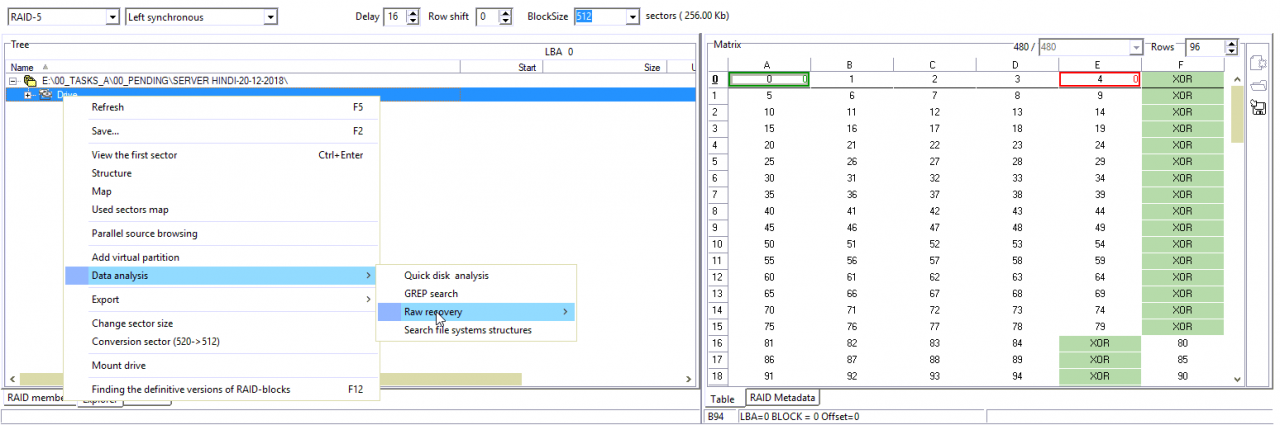
请注意,我们现在正在使用推测配置。 并且在此配置上的保护罩位置可能与建议的位置不同。
就我们而言,它们是相同的。
我们为找到的NTFS引导添加虚拟NTFS分区。
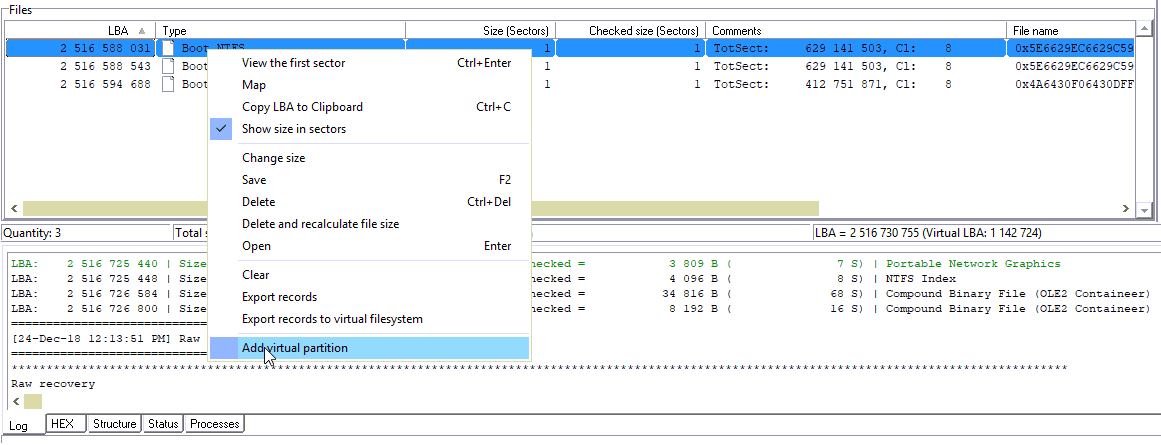

清除矩阵,然后尝试基于NTFS结构设置配置
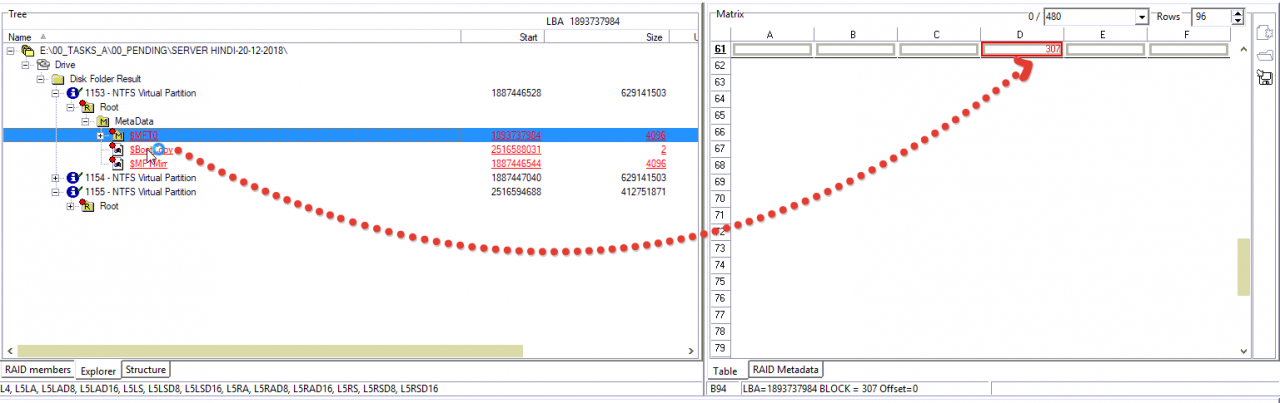
一号块完成了…
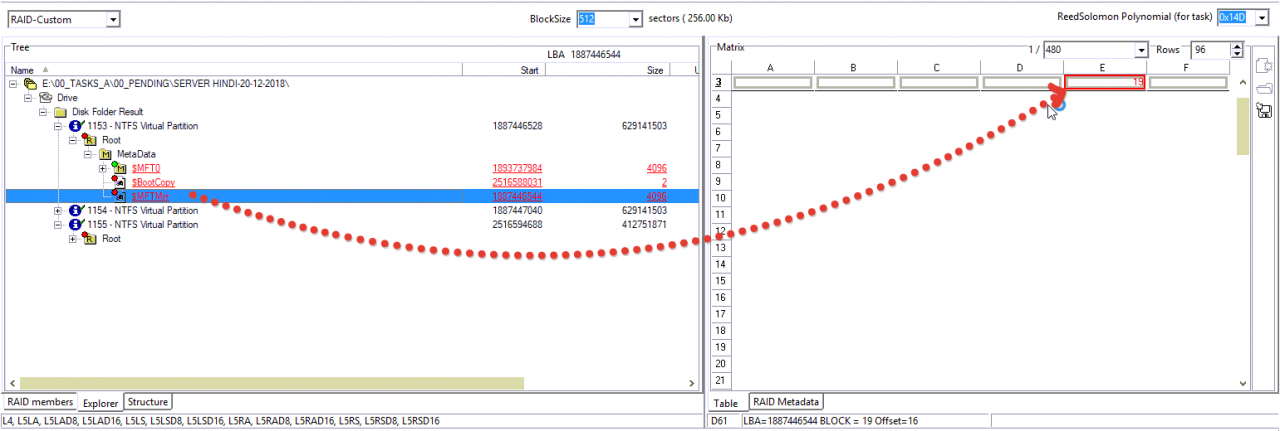
第二块…
第三个……
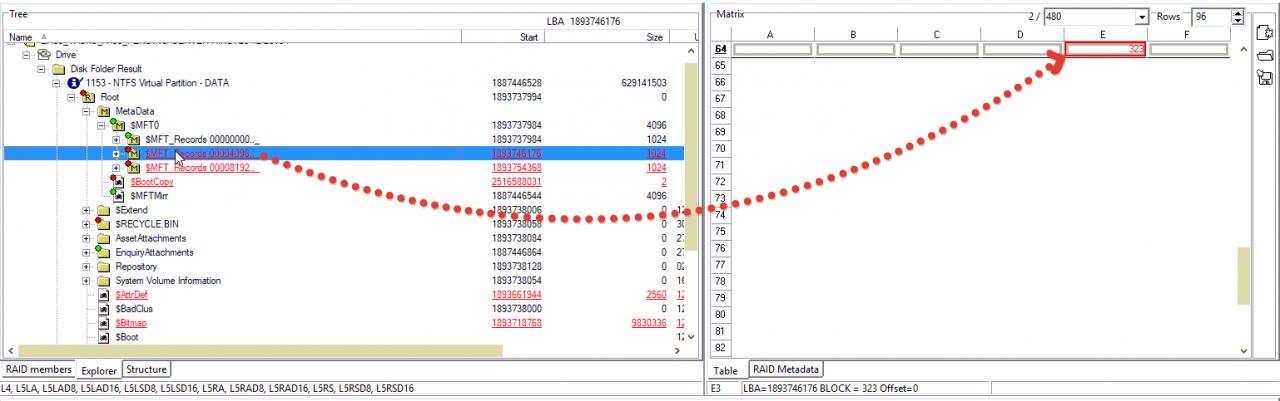
Data Extractor允许我们使用标准配置参数填充一些单元格。

完成了!
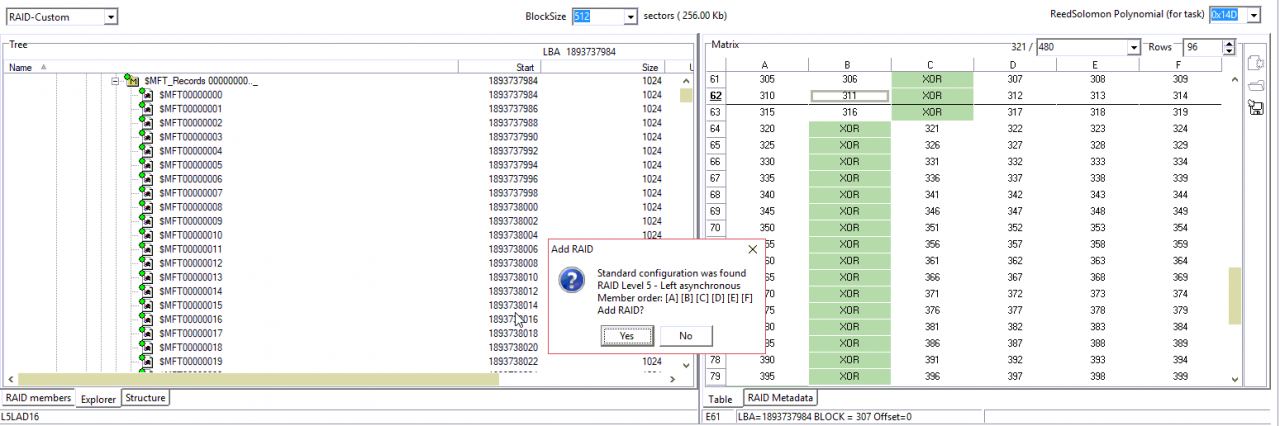
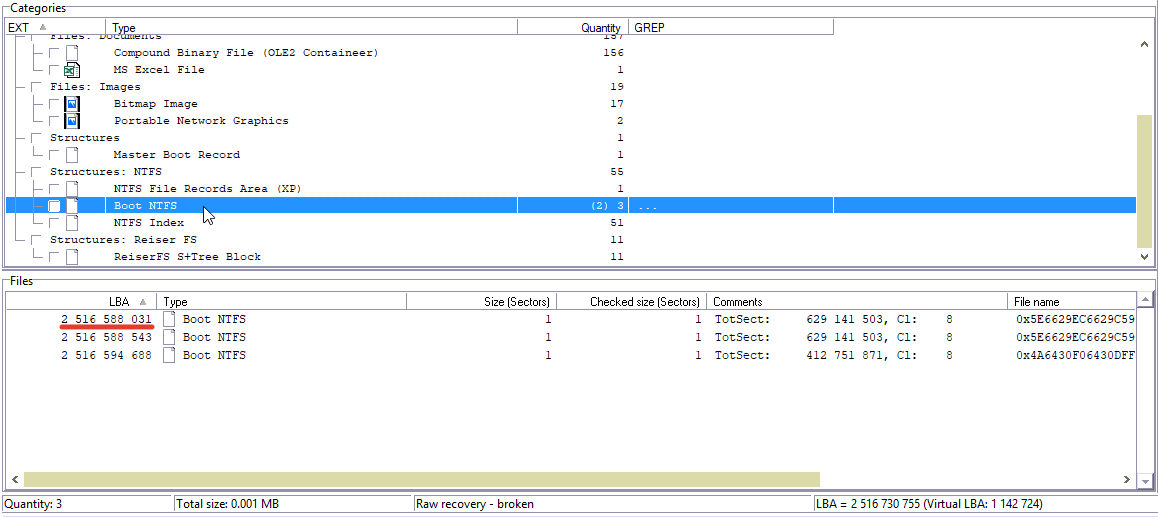
文件结构很好。

保存配置。
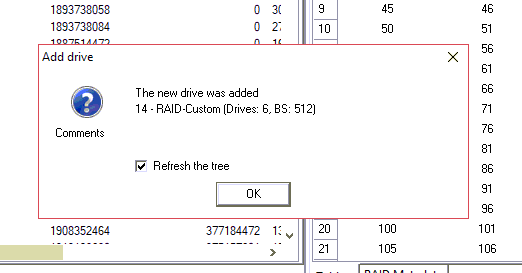
请记住,初始RAID配置已经格式化。因此,要在已保存的配置上打开NTFS分区,我们需要手动添加它。
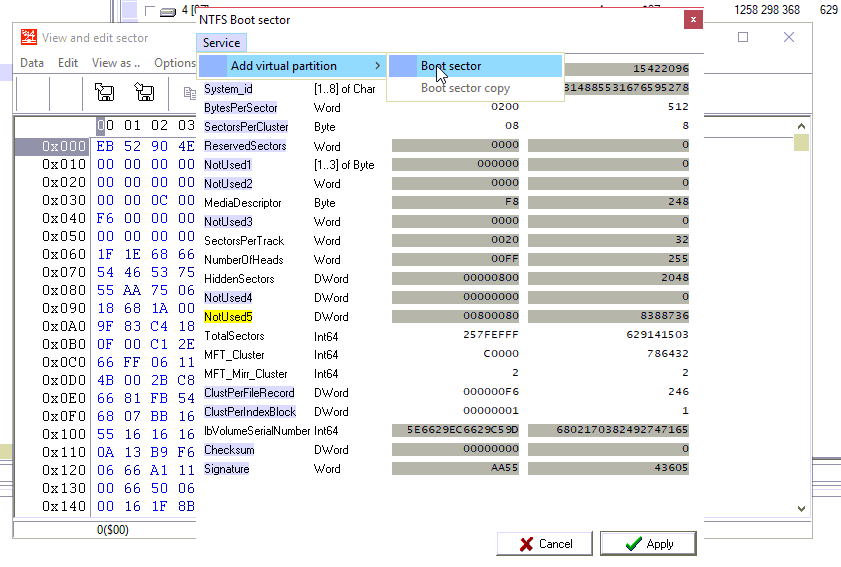
我们记得NTFS引导LBA

粘贴这个LBA在扇区编辑器
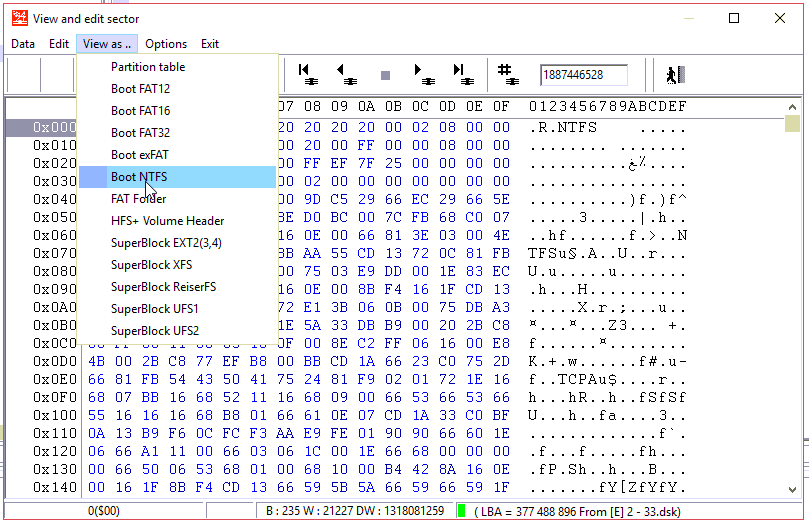
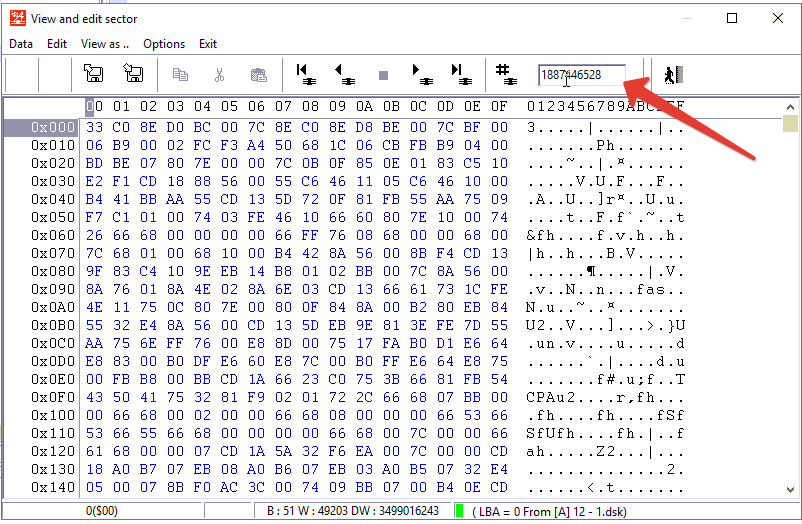 并从扇区编辑器添加NTFS分区
并从扇区编辑器添加NTFS分区
本文的主要思想是演示Data Extractor RAID Edition的强大功能。Data Extractor RAID Edition是一款灵活而复杂的数据分析和数据恢复工具。如果您想深入了解RAID案例中的数据恢复,请与我们的TS部门联系。
未经允许不得转载:苏州盘首数据恢复 » 案例研究:使用PC-3000 RAID Edition进行RAID数据恢复就像1-2-3一样容易